1.빅데이터의 배경
빅데이터 개념
빅데이터는 양(Volume)이 많고, 증가 속도(velocity)가 빠르며, 종류(variety)가 다양한 데이터이다.이것을 V3라고도 부른다.
간단히 말해, 빅데이터는 특히 새로운 데이터 소스에서 나온 더 크고 더 복잡한 데이터 세트이다. 이러한 데이터 세트는 너무 방대하여 기존의 데이터 처리 소프트웨어로는 관리 할 수 없기에 나온 해결방안이다.
비즈니스 애널리틱스(Business Analytics, BA)
비즈니스 애널리틱스는 비즈니스 기회를 얻기 위하여 데이터를 지속적/반복적으로 조사하고 분석하는 기법, 기술, 응용분야, 실무를 의미한다.
분석은 총 4단계로 설명적 분석, 진단적 분석, 예측적 분석, 예방적 분석과 같이 총 4단계로 이루어져있다.
- 설명적 분석(descriptive analytics)
- 데이터로부터 비즈니스 운영을 이해하고 해석하는 과정으로 과정으로 비즈니스 애널리틱스의 첫 단계라고 할 수 있다.
- 진단적 분석(diagnostic analytics)
- 데이터로부터 문제를 감지하고 원인을 파악하고 진단하는 목적의 비즈니스 애널리틱스 방법이다.
- 예측적 분석(predictive analytics)
- 비즈니스 의사결정을 지원하기 위하여 주어진 환경 또는 미래에서 비즈니스 운영 결과가 어떻게 발생할지 예측하는 방법으로, 최근 데이터 마이닝 및 머신러닝 기법들의 지도학습(supervised learning)이 대표적으로 활용될 수 있는 분야이다.
- 예방적 분석(prescriptive analytics)
- 최종적으로 최적의 비즈니스 의사결정 방법을 알려주고 대안을 제시하는 방법으로 전통적인 경영과학 기법들이 적용될 수 있으나, 빅데이터 분야에서는 상대적으로 아직 성숙되지 못한 분야이다.
비즈니스 인텔리전스(Business Intelligence, BI)
경영진과 경영분석가들이 데이터를 통해 합리적 의사결정을 내릴 수 있도록 데이터를 수집, 저장, 처리, 분석하는 일련의 기술, 응용시스템
데이터 웨어하우스(Data Warehouse, DW)
데이터를 분석하기 용이하도록 데이터 창고를 구축하는 것이다.

ETL(Extract, transform, load) Process
필요한 데이터를 추출(extract)하고, 적합한 형태로 통일하기 위하여 변환(transform)하여 데이터웨어하우스에 전송 또는 적재(load)하는 일렬의 절차이다.
데이터 레이크(Data Lake)
데이터 레이크는 대규모의 다양한 원시 데이터 세트를 기본 형식으로 저장하는 데이터 리포지토리 유형이다.
데이터 레이크를 사용하면 정제되지 않은 데이터를 볼 수 있다. 이때, 원시 데이터는 특정 목적을 위해 처리되지 않은 데이터를 말한다.
데이터 레이크와 데이터 웨어하우스 비교
데이터 레이크와 데이터 웨어 하우스는 둘 다 빅데이터를 위한 데이터 스토리지 리포지토리라는 것으로 종종 혼동되지만 그것만이 유일한 유사점이다.
데이터 웨어하우스는 보고를 위해 설계된 구조화된 데이터 모델을 제공한다. 데이터는 데이터 웨어하우스에 저장하기 전에 처리되어야 한다. 이때, 데이터 웨어하우스에 어떤 데이터를 포함할지 결정하는데, 이를 schema on wirte라 한다.
데이터 레이크는현재 정의된 용도가 없는 비정형 운시 데이터를 저장한다.
2.데이터마이닝 중심 빅데이터 분석 기법 개요
빅데이터 분석 기법
- 데이터 마이닝(data mining)
- 많은 양의 데이터를 효과적으로 분석하는 데 사용될 수 있는 통계, 패턴인식, 기계학습 등 여러 분야의 데이터 분석 기법들을 총칭하는 용어
- 분석 목적에 따라 분류(classification), 예측(prediction), 군집화(clustering), 연관관계(association rule), 이상치 탐지(anomaly detection) 등으로 구분
- 기계학습(machine learning)
- 컴퓨터 또는 소프트웨어가 스스로 발전할 수 있도록 설계된 알고리즘
- 기계학습 기법들은 빅데이터를 바탕으로 학습하는 지도학습(supervised learning)과 비지도학습(unsupervised learning), 그리고 데이터를 사용하지 않고 스스로 가능한 방식을 탐색하면서 학습하는 강화학습(reinforcement elarning)으로 분류
- 딥러닝(deep learning)
- 다층 신경망을 활용한 기계학습 기법이 인공지능 분야에서 급속도로 발전함
- 딥러닝 또한 신경망을 학습하기 위하여 방대한 양의 빅데이터를 활용하므로 빅데이터분석 기법으로 볼 수 있음
- 대표적인 딥러닝 기법으로 이미지나 동영상 데이터로부터 부분적인 특징들을 추출하기위한 합성곱 신경망(CNN: Convolutional Neural Network),새로운 데이터 패턴을 생성해내는 생성적 적대 신경망(GAN, Generative Adversarial Network)등이 있다.
데이터 마이닝
대량의 데이터 집합으로부터 유용한 정보를 추출하는 것이다.
수행단계는 다음과 같다.
- 문제 정의
- 정확한 목표 정의
- 데이터 수집
- 데이터 확보 및 신뢰성(veracity) 확인
- 데이터 전처리
- 모델 개발 실험 계획
- holdout 기법
- 전체 데이터에서 7:3 또는 8:2 비율로 훈련 데이터와 테스트 데이터로 나눈다.
- 훈련 데이터(training set)는 모델을 개발하기 위하여, 테스트 데이터(test set)는 모델을 평가하기 위하여 사용한다.
- 데이터의 양이 충분하지 않은 경우에는 이렇게 두 데이터로 분리하였을 때, 특이 데이터가 테스트 데이터에 포함되는가에 따라서 편중이 있을 수 있다.
- k-fold 교차검증(k-fold cross validation)
- 전체 데이터를 k-묶음으로 나눈 후, (k-1)개 묶음으로 학습시켜서 나머지 한 묶음으로 테스트를 하는 작업을 번갈아가며 총 k회 실시하는 방식
- 각 묶음이 공평하게 (k-1)회씩 학습에 사용되고, 1회씩 테스트에 사용되므로 데이터 편중에 우려가 줄어든다.
- 극단적인 교차검증은 k를 데이터 개수 N과 같도록 설정하여(k=N), 총 N번의 교차검증을 하는 방식인데, 이를 leave-one-out 교차검증이라고 부른다.
- holdout + validation 기법
- 더 객관적인 성능 평가를 하기 위하여 검증 데이터셋(validation set)를 추가하는 것으로, 훈련 데이터에 다시 hold-out 기법을 적용한 것이라고도 볼 수 있다.
- 검증 데이터셋은 훈련 데이터로 개발된 여러 모델들의 성능을 비교하는데 사용되며, 선정된 최선의 모델의 성능은 테스트 데이터셋을 이용하여 평가
- holdout + 교차검증 기법
- k-fold 교차검증에 holdout+validation 기법을 합성한 기법
- 즉, training data와 validation data에 k-분할데이터를 적용하고, testing 데이터는 고정
- holdout 기법


- 최적 모형 개발
- 성능 평가
기계학습
- 지도학습(supervised Learning)
- 분류값 또는 수치와 같은 주어진 목표값을 잘 예측하기 위하여 데이터를 학습하는 기법이다.
- 답(label)을 함께 주는 데이터 제공 : 입력 데이터 = {(입력,정답), ...}
- 유형으로는 회귀(regression)과 분류(classfication)이 있다.
- 비지도학습(Unsupervised Learning)
- 특정한 목표값이 아니라 데이터가 포함하고 있는 전반적인 특징이나 패턴을 찾기 위하여 데이터를 학습하는 기법이다.
- 입력데이터 = {입력, ...}
- 유형으로는 군집화(clustering)과 이상치 탐지(novelty detection)이 있다.
- 강화학습(Reinforcement Learning)
- 데이터가 먼저 주어지지 않고, 환경에 반응 (대응과 보상)하는 방식으로 학습
- 기계학습이지만 빅데이터 분석 기법이라기보다는 게임 플레이, 알파고등의 인공지능 기법에 포함된다.
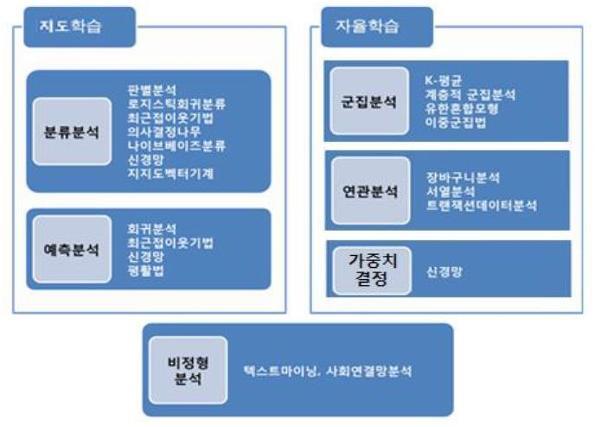
지도학습 : 분류, 회귀
분류는 주어진 데이터들을 사전에 학습한 후, 새로운 데이터 개체(instance의 특징(freature))를 바탕으로 그 개체가 속할 클래스를 예측하는 작업이다.
클래스를 알지 못하는 개체에 대하여 그 특징을 기반으로 알려진 클래스 중 하나로 가장 정확하게 할당하는 것을 목표로 한다.
예시로느 다이렉트 마켓팅, 불량 검출등이 있다.
회귀는 주어진 데이터들을 사전에 학습한 후, 새로운 데이터 개체를 바탕으로 그 개체의 목표값을 예측하는 작업이다.
목표값을 알지 못하는 개체에 대하여 그 특징을 기반으로 목표변수의 정량적 값을 가장 정확하게 예측하는 것을 목표로 한다.
예시로는 수요예측, 불량률 예층, 잔존수명(Remaining Useful Life)등이 있다.
비지도학습 : 군집화, 연관 규칙
군집화는 주어진 데이터 셋에 대하여, 유사한 데이터들끼리 같은 클러스터(cluster)로 모으고, 다른 데이터들끼리는 서로 다른 클러스터에 속하도록 데이터들을 그룹화하는 작업이다.
군집화와 분류는 그룹으로 모은다는 공통점이 있지만,
군집화은 각 개체의 범주가 군집의 정보를 모를 때, 즉 label이 없을때 데이터 자체의 특성에 대해 알고자 하는 목적으로,
분류는 label이 있을 때, 새로운 데이터의 그룹을 예측하기 위한 목적으로 하는 분석기법이다.
클러스터링을 위해서는 개체간 유사성 또는 거리를 측정할 수 있는 측도가 필요한데, 측도는 다음과 같은것들이 있다.
- 유사성 측도 : Pearson's correlation coefficient, Jaccard coefficient, Consine similarity등
- 거리 측도 : Euclidean distance, Minkowsky distance, Hamming distance등
응용분야로는 시장 세분화나 설비 상태 분류등이 있다.
연관 분석은 장바구니 데이터(merket basket data)와 같이 여러 가지 항목들으로 구성된 데이터들이 주어졌을 때, 패턴을 이해하기 위하여 항목들 간에 자주 발생하는 규칙을 생성하는 작업이다.
이상치 탐지(Anomaly Detection)는 데이터가 주어졌을 떄, 일반적인 데이터와 달리 특이하거나 이상한 행태를 보이는 이상치(anomaly) 또는 아웃라이어(outlier)데이터를 검출하는 것이ㅏ.
방법으로는 모델 기반 방법, 유사도/ 거리 기반 방법, 밀도 기반 방법등이 있다.
예시로는 신용카드 사기 탐지나 설비 이상상태 감지등이 있다.
출처: https://www.oracle.com/kr/big-data/what-is-big-data/
https://www.redhat.com/ko/topics/data-storage/what-is-a-data-lake
'빅데이터' 카테고리의 다른 글
| 빅데이터_Chapter05_Spark 설치 및 환경설정 (0) | 2022.04.27 |
|---|---|
| 빅데이터_Chapter04_Hadoop 설치 및 환경설정 (0) | 2022.04.27 |
| 빅데이터_Chapter03_Java 설치 및 환경설정 (0) | 2022.04.27 |
| 빅데이터_Chapter06_Zookeeper (0) | 2022.04.14 |
| 빅데이터_chapter02_하둡과 데이터과학 (0) | 2022.03.18 |