Spark
하둡에서 하나의 데이터셋이 반복되어 재사용되는 작업의 효율적 처리를 위한 프레임워크에서 탄생한 Spark는 인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크이다.
Spark는 변환 및 이들 간의 종속성을 나타내는 RDD와 DAG의 개념을 기반으로 구축되었다.
스파크의 특징은 다음과 같다.
- 빠르고 다양한 데이터 처리
- 인메모리(In-Memory)기반의 빠른처리
- DAG(Directed Acyclic Graph)기반 처리엔진 보유
- Ease of Use
- 다양한 언어 지원(Java, Scala, Python, R)을 통한 사용의 편이성 제공
- Java를 제외한 언어에 대해 REPS(Read, Evaluate, Print, Loop)기능의 쉘을 제공
- 다양한 라이브러리 제공
- SparkSQL : 스파크 응용개발을 위한 SQL 구문 또는 데이터프레임
- Spark Streaming : 실시간 데이터 스트리밍 지원
- Spark Mlib : 머신러닝 응용 개발 지원
- Spark GraphX : 그래프처리와 그래프 알고리즘 지원
Apache Spark의 작동 방식에 대해 자세히 알아보기 전에 Apache Spark의 용어들을 정의하자.
| 용어 | 내용 |
| Job(작업) | HDFS 또는 로컬에서 입력을 읽고 데이터에 대해 계산을 수행하고 출력 데이터를 작성하는 코드 조각이다. |
| Stages(단계) | Jobs는 여러 Stages로 나뉜다. 단계는 Map 또는 Reduce 단계로구분된다. 단계는 계산 경계에 따라 구분되며 단일 단계에서 모든 계산(연산자)을 업데이트할 수 없다. 여러 단계에 걸쳐 발생한다. |
| Tasks(작업) | 각 Stage(단계)에는 몇 가지 Task(작업)이 있다. 이때, 한 파티션 당 하나의 Task(작업)이 존재한다. Executor에서 데이터 파티션 중 하나의 Task(작업)이 실행된다. |
| DAG | 방향성 비순환 그래프(Directed Acyclic Graph)를 나타낸다. |
| Executor | Task 실행을 담당하는 프로세스이다. |
| Master | driver 프로그램이 실행되는 머신 |
| Slave | Executor 프로그램이 실행되는 머신 |
Spark 구조
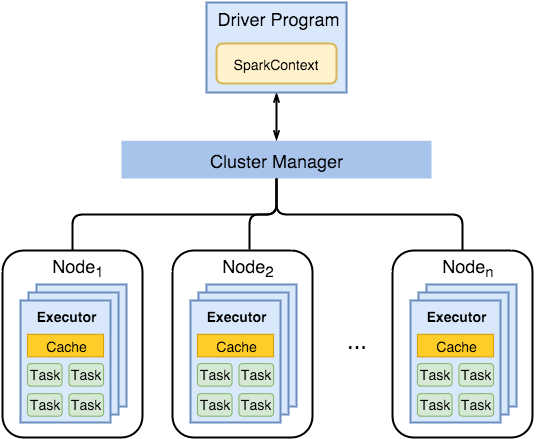
- Spark Driver
- 사용자 어플리케이션을 실행하기 위한 별도의 프로세스이다.
- Jobs(작업) 실행을 예약하고 Cluster Manager와 통신하기 위해 SparkContext를 만든다.
- Executors
- 드라이버가 예약한 작업을 실행한다.
- 계산 결과를 메모리, 디스크 또는 off-heap에 저장한다.
- 스토리지 시스템과 상호작용한다.
- Cluster Manager
- Mesos
- Yarn
- Spark Standalone
Spark Driver
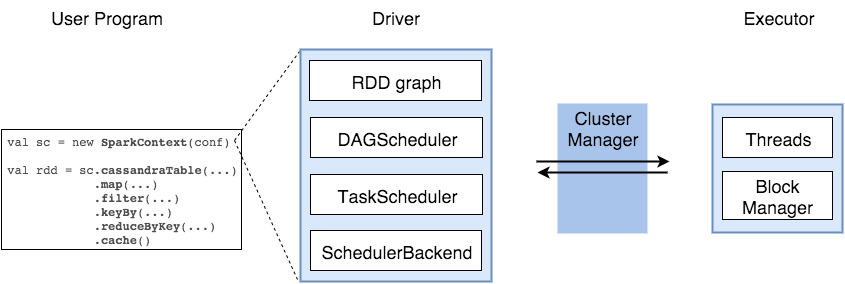
Spark Driver에는 사용자 코드를 실제 작업으로 변환시키는 여러 구성요소들을 갖고 있다.
- SparkContext
- Spark Cluster에 대한 연결을 나타내며 해당 클러스터에서 RDD, 누산기 및 브로드캐스트 변수를 생성하는 데 사용할 수 있다.
- DAGS Scheduler
- 각 Job에 대한 Stage의 DAG를 계산하고 이를 Task Scheduler에 전송한다.
Task의 기본 위치를 결정하고 작업을 실행하기 위한 최소 스케줄을 찾는다.
- 각 Job에 대한 Stage의 DAG를 계산하고 이를 Task Scheduler에 전송한다.
- Task Scheduler
- 클러스터에 작업을 보내고, 실행하고, 오류가 있는 경우 재시도 하는 여러 역할을 한다.
- Scheduler Backend
- 다양한 구현(Mesos, Yarn등)에 플러그인할 수 있는 스케줄링 시스템용 백엔드이다.
- Block Manager
- 블록을 로컬 및 원격으로 다양한 저장소(메모리, 디스크등)에 넣고 검색하기 위한 인터페이스를 제공한다.
Spark는 다음과 같이 작동한다.

- Scala Interpreter를 통해 해석 및 수정한다.
- Spark 콘솔에 코드를 입력하면(RDD 생성 및 연산자 적용) Spark는 연산자 그래프를 생성한다.
- 사용자가 작업(action)을 실행하면 그래프가 DAG Scheduler에 제출된다.
- DAG 스케줄러는 연산자 그래프를 Stage로 나누고, DAG를 계산한다.
이때, Stage는 입력 데이터의 파티션을 기반으로 하는 Task로 구성된다. - DAG 스케줄러의 최종 결과 stage를 Task Scheduler로 전송한다.
- Task 스케줄러는 Cluster Manager를 통해 작업을 실행한다.
'빅데이터' 카테고리의 다른 글
| 빅데이터_Chapter?_SparkRDD (0) | 2022.06.06 |
|---|---|
| 빅데이터_Chapter06_RDD (0) | 2022.05.11 |
| 빅데이터_Chapter05_Spark 설치 및 환경설정 (0) | 2022.04.27 |
| 빅데이터_Chapter04_Hadoop 설치 및 환경설정 (0) | 2022.04.27 |
| 빅데이터_Chapter03_Java 설치 및 환경설정 (0) | 2022.04.27 |