그룹함수
그룹함수는 복수행 함수라고도 하며, 여러행에 대한 정보를 조회하는 함수이다.
count() : 레코드 건수
null값을 제외한 레코드의 건수를 카운트하는 함수이다.
표기는 다음과 같다. count(컬럼)
select count(*) as "전체인원수", count(bonus) as "보너스" from professor;위 코드는 professor 테이블에서 교수 전체 인원수와 교수 중 보너스를 받은 교수의 인원수를 조회하는 코드이다.
이 때, 보너스 컬럼값이 null이면 counting에서 빠지기에 전체 인원수에서 보너스가 null값인 교수를 제한것이 count(bonus)가 될 것이다.
group by : 그룹함수 처리명령어
group by함수는 컬럼의 데이터를 기준으로 레코드를 그룹화한다.
그룹함수와 컬럼의 값을 조회하기 위해서는 반드시 조회되는 컬럼으로 group by를 설정해야한다.
표기는 다음과 같다. group by 컬럼
select grade, count(*) from student group by grade;위 코드는 학생이라는 테이블에서 학년과 학년 별 학생수를 출력하는 코드이다.
이때 group by 와 그룹함수 count를 같이 사용하여 전체 학생수를 count로 조회하고, 이를 group by로 수를 나뉘어 출력한다.
sum(), avg(), max(), min()
sum() : 합계
avg() : 평균
max(), min : 최대,최소
--professor테이블의 교수들의 월급 총합
select sum(pay) from professor;
--부서별 교수 평균 월급
--단, null값인 경우 제외한다.
select deptno,avg(pay) from professor group by deptno;
--교수 중 최대, 최소 월급
select max(pay), min(pay) from professor;
having 구문
having함수는 그룹함수의 조건문이다.
select grade, max(height), min(height), avg(height) from student
group by grade
having avg(height) >= 170;위 코드는 학년별로 최대 최소 평균 키를 조회하는데 이때, having 구문을 사용하여 평균키가 170이상인 학년만 조회를 한 코드다.
그룹에서 조검문은 where이 아닌 having구문을 사용한다.
그룹함수의 순서는 다음과 같다.
- select 컬럼명들 || *(모든컬럼) from 테이블명 -> 필수
- [where 조건문] -> 레코드 선택의 조건
- [group by 컬럼] -> 그룹함수 사용시 그룹화 기준 컬럼
- [having 조건문] -> 그룹함수 조건문
- [order by 컬럼명||별명||컬럼순서 [desc || asc]] -> sql문 맨 뒤에 오며 컬럼 순서 정렬
문제
--1.주민번호를 기준으로 남학생과 여학생의
--최대키, 최소키, 평균키를 출력하기
--주민번호 7번째 자리가 1: 남학생, 2: 여학생
select decode(substr(jumin,7,1),1,'남학생',2,'여학생') as 성별,
max(height),min(height),round(avg(height),2)
from student
group by substr(jumin,7,1);
--1.주민번호 기준 월별 인원 수 조회하기
select substr(jumin,3,2) as 월,count(*) as 인원수 from gogak
group by substr(jumin,3,2)
order by 월;
--2. 주민번호 기준 성별 인원 수 조회하기
select decode(substr(jumin,7,1),1,'man',2,'woman') as 성별, count(*) from gogak
group by substr(jumin,7,1);
--1.학생들의 전화번호의 지역번호 조회하기 및 인원수 조회하기
select substr(tel,1,instr(tel,')'))as 지역번호, count(*) as 인원수 from student
group by substr(tel,1,instr(tel,')'));
stddev() : 표준편차 함수, variance() : 분산 함수
select stddev(height) as 키편차, stddev(weight) as 체중편차,
variacne(height) as 키분산, variance(weight) as 체중분산
from student;rewnum : 레코드 조회 순서, rowid : 레코드 고유의 id.
- rownum은 질의문 결과에 대해서 논리적인 일렬번호를 부여한다.
- 조회되는 행 수를 제한할 때 많이 사용한다.
- order by 구문 이전에 미리 설정. order by 구문으로 값 변경 안됨.
- rowid는 데이터를 구분할 수 있는 유일한 값이다. 또한 rowid를 통해서 데이터가 어떤 데이터 파일, 어느 블록에 저장되어 있는지 알 수 있다.
- rowid는 테이블에 데이터를 입력하면 자동으로 생성되는 값이다.
select name, grade,rownum, rowid from student;
--학생 정보를 5건만 조회하기
select * from student where rownum <= 5;
--학생 테이블의 rownum값이 6이상인 레코드 조회하기
--rownum은 순차대로 부여가 되기에 1부터 읽어야한다.
--고로 해당 코드를 실행하면 아무것도 실행이 되지않는다.
select * from student where rownum > 5;
join
여러개의 테이블을 연결하여 조회.
cross join(카티션곱)
- 오라클 조인 방식
- 두개의 테이블의 모든 레코드의 곱의 갯수로 레코드 조회
- 조회되는 레코드 갯수가 두 테이블의 레코드의 곱이므로 사용시 주의
--14건
select count(*) from emp;
--4건
select count(*) from dept;
--14*4 = 총 56건
select * from emp,dept order by empno;위 콛는 emp 테이블과 dept 테이블을 cross join하는 코드이다.
emp는 14건 dept는 4건으로 두 테이블을 cross join한다면 총 56건이된다.
이는 레코드의 곱이 되는 join으로 사용이 복잡하여 잘 사용하지 않고 사용 시 주의해야한다.
select ename, deptno, name from emp e, dept;위 코드는 cross join하여 몇몇 컬럼만 조회한다 하지만 이는 에러가 발생한다.
이유는 deptno라는 컬럼은 emp와 dept 테이블에 둘다 존재하므로 이를 올바르게 출력하기 위해 [테이블명.컬럼명]이와 같은 형식으로 작성해야한다. dept.deptno
더 간단하게는 컬럼의 별명을 지어주 듯 테이블의 별명을 만들어서 지정할 수도 있다.
equi join(등가 조인)
- 두개의 테이블을 연결해주는 연결 컬럼으로 레코드 조회
- 연결 컬럼의 값이 같은 경우 연결
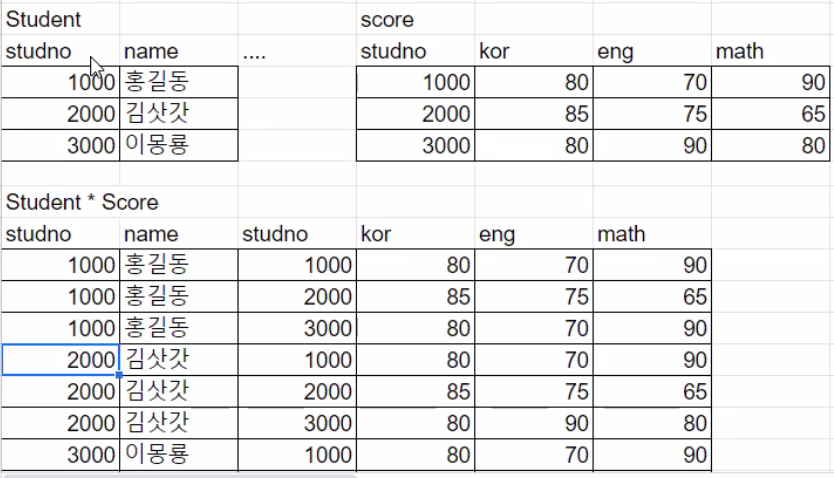
위 사진은 두 테이블을 cross join할 경우이다. 그림과 같이 '홍길동'이라는 학생에게 총 3가지 studno가 부여된다.
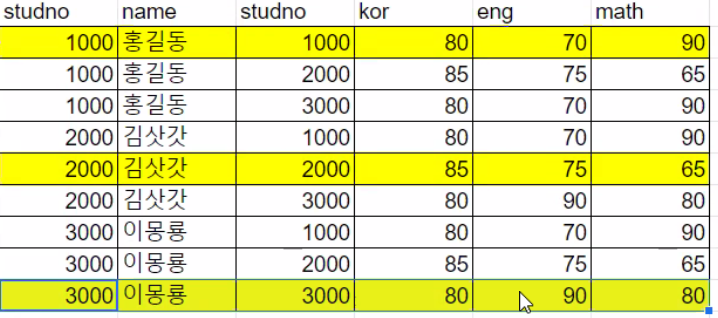
하지만 등가 조인을 할 경우 위 테이블에서 노란색으로 칠해진 것들이 조인되는 것이다.
select s.studno, s.name, sc.kor from student s, score sc where s.studno = sc.studno;equi join은 오라클 방식과 ANSI방식 이 둘로 나눌 수 있다. 차이점은 다음과 같다.
--오라클 방식
select s.name, s.deptno1, d.dname
from student s, department d
where s.deptno1 = d.deptno;
--ANSI 방식
select s.name, s.deptno1, d.dname
from student s join department d
on s.deptno1 = d.deptno;문제
emp 테이블의 사원이름, 부서코드(deptno)와 dept테이블의 부서이름 조회하기
select ename, e.deptno, dname from emp e,dept d where e.deptno = d.deptno;
사원이름은 emp테이블에만 존재하기에 ename을, dname은 dept테이블에만 존재하기에 dname을 조회하지만
deptno은 dept테이블과 emp테이블 둘 다에 존재하기에 둘 중 하나의 deptno으로 결정을 해줘야 한다.
그리고 where조건문으로 deptno이 같은 것 끼리 join을 시켜준다면 위 사진과 같이 출력한다.
문제2.
학생테이블과 교수테이블을 이용하여 학생의 이름, 지도 교수번호, 지도 교수이름 조회하기.
단, 지도교수가 없는 학생은 조회하지 않는다.
--오라클 방식
select s.name,p.profno, p.name from student s, professor p
where s.profno = p.profno;
--ANSI 방식
select s.name,p.profno, p.name from student s join professor p
on s.profno = p.profno;
/*
1. 학과별로 평균 몸무게와 학생 수를 출력하되 평균 몸무게의 내림차순으로 정렬하여라.
[결과]
학과코드 평균몸무게 학생수
---------- ---------- ----------
201 67 6
102 64.25 4
202 62.5 2
101 60 4
301 60 2
103 51.5 2
*/
select deptno1 as 학과코드, avg(weight) as 평균몸무게, count(*) as 학생수
from student
group by deptno1 order by 평균몸무게 desc;
/*
2. 학생테이블의 birthday를 기준으로 월별로 태어난 인원수 출력하기
[결과]
합계 1월 2월 3월 4월 5월 6월 7월 8월 9월 10월 11월 12월
------- ------- -------- -------- -------- -------- -------- -------- -------- -------- --------- --------- ---------
20 3 3 2 2 0 1 0 2 2 2 1 2
*/
select count(*)as "합계",
sum(decode(substr(birthday,4,2),'01',1,0)) as "1월",
sum(decode(substr(birthday,4,2),'02',1,0)) as "2월",
sum(decode(substr(birthday,4,2),'03',1,0)) as "3월",
sum(decode(substr(birthday,4,2),'04',1,0)) as "4월",
sum(decode(substr(birthday,4,2),'05',1,0)) as "5월",
sum(decode(substr(birthday,4,2),'06',1,0)) as "6월",
sum(decode(substr(birthday,4,2),'07',1,0)) as "7월",
sum(decode(substr(birthday,4,2),'08',1,0)) as "8월",
sum(decode(substr(birthday,4,2),'09',1,0)) as "9월",
sum(decode(substr(birthday,4,2),'10',1,0)) as "10월",
sum(decode(substr(birthday,4,2),'11',1,0)) as "11월",
sum(decode(substr(birthday,4,2),'12',1,0)) as "12월"
from student;
/*
3. 학과별 교수 수가 2명 이하인 학과 번호, 교수 수를 출력하여라
[결과]
DEPTNO COUNT(*)
---------- ----------
201 2
301 2
202 2
203 1
*/
select deptno,count(*) from professor group by deptno having count(*) <= 2;
/*
4.직급별로 평균 급여가 320보다 크면 '우수', 작거나 같으면 '보통'을 출력하여라
[결과]
POSITION 급여
---------------------------------------- ------------
정교수 우수
전임강사 보통
조교수 우수
*/
select position,
case
when avg(pay)> 320 then '우수'
else '보통'
end
from professor group by position;
/*
5. 부서중 최대인원을 가진 부서의 인원수와 최소인원을 가진 부서의 인원수 출력하기
[결과]
최대인원 최소인원
---------- ----------
3 1
*/
select max(count(deptno)) as 최대인원,min(count(deptno))as 최소인원 from professor group by deptno;
/*
6. 교수테이블에서 평균 급여가 350이상인 부서의 부서코드, 평균급여, 급여합계를 출력하기
[결과]
부서코드 평균급여 급여합계
---------- ---------- ----------
102 363.333333 1090
201 450 900
101 400 1200
203 500 500
103 383.333333 1150
*/
select deptno,avg(pay),sum(pay) from professor group by deptno having avg(pay) >= 350;
-- 7. 4학년 학생의 이름 학과번호, 학과이름 출력하기
select s.name, d.deptno, d.dname from student s , department d
where s.deptno1 = d.deptno and s.grade = 4;
-- 8. 오나라 학생의 이름, 학과코드1,학과이름,학과위치 출력하기
select s.name, s.deptno1,d.dname,d.build from student s, department d
where s.deptno1 = d.deptno and s.name = '오나라';
-- 9. 학번과 학생 이름과 소속학과이름을 학생 이름순으로 정렬하여 출력
select studno,name,dname from student,department
where student.deptno1 = department.deptno
order by name;
-- 10. 교수별로 교수 이름과 지도 학생 수를 출력하기.
select p.name as 교수이름,count(*) as 지도학생 from student s,professor p
where s.profno = p.profno
group by p.name;
-- 11. 성이 김씨인 학생들의 이름, 학과이름 학과위치 출력하기
select s.name,d.dname,d.build from student s, department d
where s.deptno1 = d.deptno and name like '김%';'데이터베이스' 카테고리의 다른 글
| 데이터베이스_K_Digital_chapter07 (0) | 2022.08.19 |
|---|---|
| 데이터베이스_K_Digital_chapter05 (0) | 2022.08.18 |
| 데이터베이스_K_Digital_chapter03 (0) | 2022.08.16 |
| 데이터베이스_chapter01_데이터베이스 시스템 (0) | 2022.08.12 |
| 데이터베이스_10.정규화 (0) | 2021.11.08 |