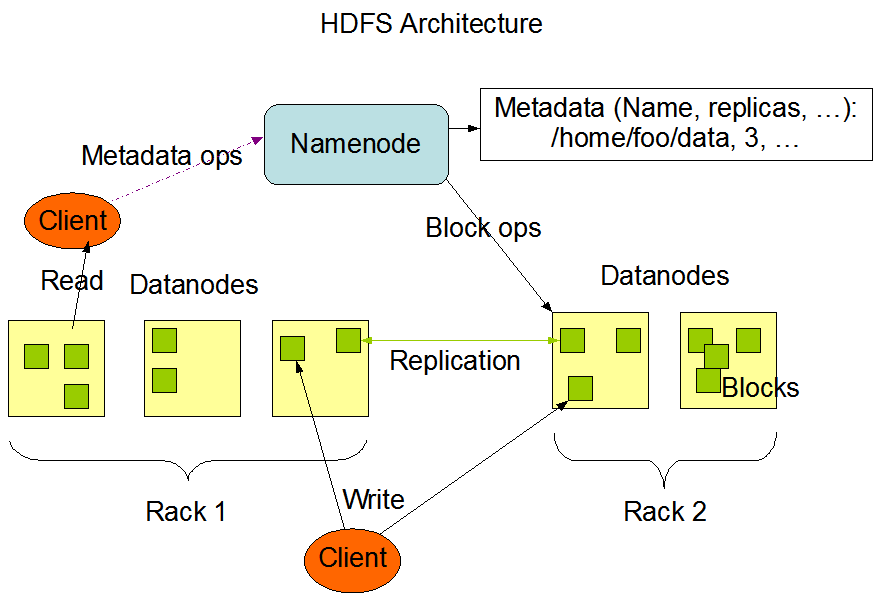
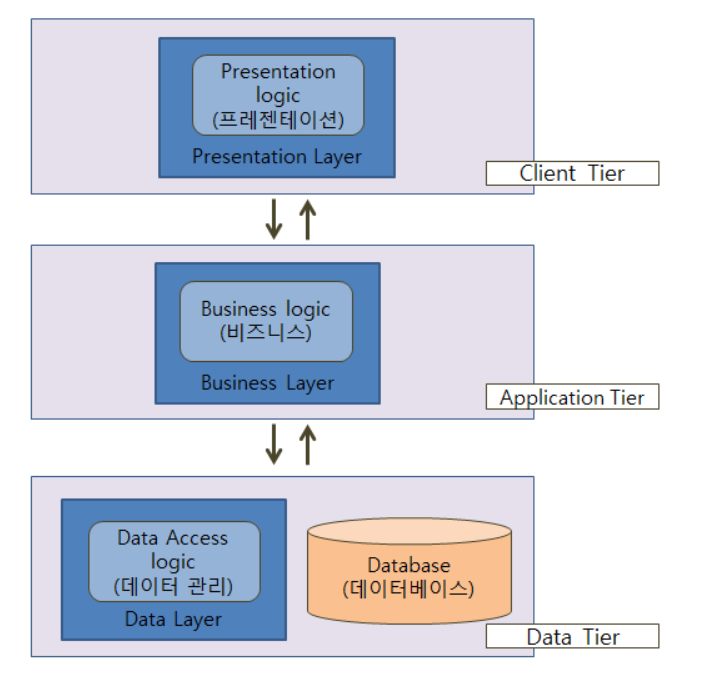
클라우드 컴퓨팅은 인터넷("클라우드")을 통해 서버, 스토리지, DB, 네트워킹, 소프트웨어, 분석, 인텔리전스 등의 컴퓨팅 서비스를 제공하는 것이다. 즉, 인터넷만 된다면 언제 어디서나 필요한 만큼의 컴퓨팅 자원을 필요한 시간만큼 인터넷을 통하여 활용할 수 있다는 것이다. 클라우드 컴퓨팅의 이점 클라우드 컴퓨팅은 그 동안 기업이 IT 리소스에 접근하던 방식을 크게 바꾸어 놓았다. 클라우드 컴퓨팅의 이점을 정리하면 다음과 같다. 접속 용이성 시간과 장소에 상관없이 인터넷을 통해 클라우드 서비스 이용 가능 다양한 기기로 서비스 이용 가능 유연성(확장성) 클라우드 공급자는 갑작스러운 이용량 증가나 이용자 수 변화에 신속하고 유연하게 대응할 수 있기 때문에 중단없이 서비스를 이용할 수 있음 주문형 셀프서비스(..